- Key/Value and a row store. No need for pre-defined schemas, even rows within a ColumnFamily are not required to always follow the same naming schema.
- designed to handle large amounts of data spread across many commodity servers while remaining highly available. Cassandra is loosely defined as a key/value store where one key can map to one or more values.
- Is architected to handle real-time big-data workloads across multiple data centers with no single point of failure. Every node in a cluster can serve any request.
- Cassandra is typically classified as an AP system, meaning that availability and partition tolerance are generally considered to be more important than consistency in Cassandra. But Cassandra can be tuned with replication factor and consistency level to also meet C.
- Cassandra supplies linear scalability, meaning that capacity may be easily added simply by adding new nodes online.
- Schema-less if needed.
- Homogenous Environment - each and every Cassandra node contains everything required to complete a cluster.
- Tunable Consistency
Configuration - (Cassandra.yaml)
# Cluster_name
# num_tokens - default 256 - This means the amount of data in propotion to the cluster this node owns.
# initial_token - default None.
When setting up a new cluster, it is important to manually calculate the tokens for each node that will be in the cluster.
#authenticator - Default: org.apache.cassandra.auth.AllowAllAuthenticator
It is recommended to use a replication factor of 2 or higher when using the PasswordAuthenticator to prevent data loss in the event of an outage.
#authorizer
Default: org.apache.cassandra.auth.AllowAllAuthorizer.
# permissions_validity_in_ms - Default: 2000
If permissions do not change very often, increase this value to increase the read/write performance.
#partitioner
Default: org.apache.cassandra.dht.Murmur3Partitioner.
It is important to note that when using the ordered partitioners such as ByteOrdered pr CollatingOPP, the ability to do range slices is increased but may also lead to hot spots. If you change this parameter, you will destroy all data in the data directories.
#data_file_directories - Default: /var/lib/cassandra/data.
Cassandra should store the data on disk.
#commitlog_directory Default: /var/lib/cassandra/commitlog.
This value should reside on a different volume from the data_file_directories.
#disk_failure_policy - Default: stop .
#saved_caches_directory - Default: /var/lib/cassandra/saved_caches.
Specifies the directory in which to store the saved caches.
#commitlog_sync - Default: periodic.
Cassandra will not acknowledge writes until the batch has been fsynced.
#commitlog_sync_period_in_ms - Default: 10000. Specifies the time in which Cassandra will fsync writes to disk. When
using batch syncs, this value should be low as writes will block until the sync happens.
#commitlog_segment_size_in_mb - Default: 32.
This specifies how large the CommitLog will grow before a new file is created.
#seed_provider- Default: org.apache.cassandra.locator.SimpleSeedProvider.
When running a multiple-node cluster, it is important to have as many seeds as possible so new nodes will be able to bootstrap in the event of an outage of a seed node.
#concurrent_reads -Default: 32.
A general rule of thumb is to set this value to 16 * the number of disks in use by data_file_directories.
#concurrent_writes - Default: 32. The number of concurrent writes. Because writes are appended to the CommitLog, they are almost never #I/O bound. The general rule of thumb for concurrent writes is 16 * the number of cores in the machine.
#memtable_total_space_in_mb - Default: not specified.
When specified, Cassandra will flush the largest MemTable when this limit has been reached. When left unspecified, Cassandra will flush the largest MemTable when it reaches one-third of the heap.
#listen_address - Default: localhost.
This is the address that the host listens on. When left unspecified, the listen address will default to the local address. In most cases, this will work. If left at localhost, other nodes may not be able to communicate.
- Need to know the read/write patterns before you create your data model. This also applies to indexes. Indexes in Cassandra are a requirement for specific types of queries, unlike a relational database where indexes are a performance-tuning device.
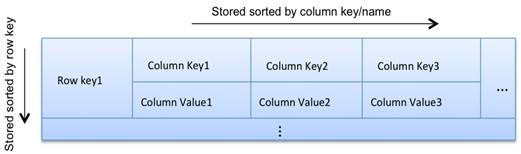
-
Creating a table in Cassandra, also tells it how to store and distribute the data. This is done via the primary key definitiion.
-
When there are multiple fields in the PRIMARY KEY , as is the case with compound keys,the first field is the partition key (how the data is distributed) and the subsequent fields are known as the clustering keys (how the data is stored on disk).
-
Rows are not segmented accross nodes. This means that the entire row will exist in a particular node, this may cause read/write hotspots due to spikes in writes/reads for that particular row.
- Model usage and queries, not the data;
- Denormalization and duplication of data are not bad—in fact, they are recommended.
- Collections can be very powerful, but they may impact performance when it comes to very large data sets.
Understanding how CQL maps to Cassandra's internal data structure
- Cassandra is a Dynamo system. it divides a hash ring into a several chunks, and keeps N replicas of each chunk on different nodes. It uses tunable quorums, hinted handoff, and active anti-entropy to keep replicas up to date.
- Operating Cassandra
- Inernals from Cassandra Wiki
- Learn Cassandra
- Practical Cassandra - A developer's Approach
- Amazon Dynamo Whitepaper
- Google Big Table White paper