-
NETWORK
# 指定 redis 只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求 bind 127.0.0.1 #是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问, 拒绝外部访问。要是开启了密码和bind,可以开启。否则最好关闭,设置为no protected-mode yes #redis监听的端口号 port 6379 #此参数确定了TCP连接中已完成队列(完成三次握手之后)的长度, 当然此值必须不大于Linux系统定义 的/proc/sys/net/core/somaxconn值,默认是511,而Linux的默认参数值是128。当系统并发量大并且客户端 速度缓慢的时候,可以将这二个参数一起参考设定。该内核参数默认值一般是128,对于负载很大的服务程序来说 大大的不够。一般会将它修改为2048或者更大。在/etc/sysctl.conf中添加:net.core.somaxconn = 2048, 然后在终端中执行sysctl -p tcp-backlog 511 #此参数为设置客户端空闲超过timeout,服务端会断开连接,为0则服务端不会主动断开连接,不能小于0 timeout 0 #tcp keepalive参数。如果设置不为0,就使用配置tcp的SO_KEEPALIVE值,使用keepalive有两个好处:检测挂 掉的对端。降低中间设备出问题而导致网络看似连接却已经与对端端口的问题。在Linux内核中,设置了 keepalive,redis会定时给对端发送ack。检测到对端关闭需要两倍的设置值 tcp-keepalive 300 #是否在后台执行,yes:后台运行;no:不是后台运行 daemonize yes #redis的进程文件 pidfile /var/run/redis/redis.pid #指定了服务端日志的级别。级别包括:debug(很多信息,方便开发、测试),verbose(许多有用的信息, 但是没有debug级别信息多),notice(适当的日志级别,适合生产环境),warn(只有非常重要的信息) loglevel notice #指定了记录日志的文件。空字符串的话,日志会打印到标准输出设备。后台运行的redis标准输出是/dev/null logfile /usr/local/redis/var/redis.log #是否打开记录syslog功能 # syslog-enabled no #syslog的标识符。 # syslog-ident redis #日志的来源、设备 # syslog-facility local0 #数据库的数量,默认使用的数据库是0。可以通过”SELECT 【数据库序号】“命令选择一个数据库,序号从0开始 databases 16
-
SNAPSHOTTING
下边持久化会介绍到
-
REPLICATION
# 复制选项,slave复制对应的master。 # replicaof <masterip> <masterport> #如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来 配置master的密码,这样可以在连上master后进行认证。 # masterauth <master-password> #当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为 yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no, INFO,replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG,SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB,COMMAND, POST, HOST: and LATENCY命令之外的任何请求 都会返回一个错误”SYNC with master in progress”。 replica-serve-stale-data yes #作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议) #replica-read-only yes # 是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者 重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建 一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进 程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能 共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。 repl-diskless-sync no #diskless复制的延迟时间,防止设置为0。一旦复制开始,节点不会再接收新slave的复制请求直到下一个rdb传输。 所以最好等待一段时间,等更多的slave连上来 repl-diskless-sync-delay 5 #slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。 # repl-ping-slave-period 10 # 复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时 # repl-timeout 60 #是否禁止复制tcp链接的tcp nodelay参数,可传递yes或者no。默认是no,即使用tcp nodelay。如果 master设置了yes来禁止tcp nodelay设置,在把数据复制给slave的时候,会减少包的数量和更小的网络带 宽。但是这也可能带来数据的延迟。默认我们推荐更小的延迟,但是在数据量传输很大的场景下,建议选择yes repl-disable-tcp-nodelay no #复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完 全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状 态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有 slave的一段时间,内存会被释放出来,默认1m # repl-backlog-size 1mb # master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。 # repl-backlog-ttl 3600 # 当master不可用,Sentinel会根据slave的优先级选举一个master。最低的优先级的slave,当选master。 而配置成0,永远不会被选举 replica-priority 100 #redis提供了可以让master停止写入的方式,如果配置了min-replicas-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失。设置为0是关闭该功能 # min-replicas-to-write 3 # 延迟小于min-replicas-max-lag秒的slave才认为是健康的slave # min-replicas-max-lag 10 # 设置1或另一个设置为0禁用这个特性。 # Setting one or the other to 0 disables the feature. # By default min-replicas-to-write is set to 0 (feature disabled) and
-
SECURITY
#requirepass配置可以让用户使用AUTH命令来认证密码,才能使用其他命令。这让redis可以使用在不受信任的 网络中。为了保持向后的兼容性,可以注释该命令,因为大部分用户也不需要认证。使用requirepass的时候需要 注意,因为redis太快了,每秒可以认证15w次密码,简单的密码很容易被攻破,所以最好使用一个更复杂的密码 # requirepass foobared #把危险的命令给修改成其他名称。比如CONFIG命令可以重命名为一个很难被猜到的命令,这样用户不能使用,而 内部工具还能接着使用 # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 #设置成一个空的值,可以禁止一个命令 # rename-command CONFIG ""
-
CLIENTS
# 设置能连上redis的最大客户端连接数量。默认是10000个客户端连接。由于redis不区分连接是客户端连接还 是内部打开文件或者和slave连接等,所以maxclients最小建议设置到32。如果超过了maxclients,redis会给 新的连接发送’max number of clients reached’,并关闭连接 # maxclients 10000
-
MEMORY MANAGEMENT
redis配置的最大内存容量。当内存满了,需要配合maxmemory-policy策略进行处理。注意slave的输出缓冲区 是不计算在maxmemory内的。所以为了防止主机内存使用完,建议设置的maxmemory需要更小一些 maxmemory 122000000 #内存容量超过maxmemory后的处理策略。 #volatile-lru:利用LRU算法移除设置过过期时间的key。 #volatile-random:随机移除设置过过期时间的key。 #volatile-ttl:移除即将过期的key,根据最近过期时间来删除(辅以TTL) #allkeys-lru:利用LRU算法移除任何key。 #allkeys-random:随机移除任何key。 #noeviction:不移除任何key,只是返回一个写错误。 #上面的这些驱逐策略,如果redis没有合适的key驱逐,对于写命令,还是会返回错误。redis将不再接收写请求,只接收get请求。写命令包括:set setnx setex append incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby getset mset msetnx exec sort。 # maxmemory-policy noeviction # lru检测的样本数。使用lru或者ttl淘汰算法,从需要淘汰的列表中随机选择sample个key,选出闲置时间最长的key移除 # maxmemory-samples 5 # 是否开启salve的最大内存 # replica-ignore-maxmemory yes
-
LAZY FREEING
#以非阻塞方式释放内存 #使用以下配置指令调用了 lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no replica-lazy-flush no
-
APPEND ONLY MODE
详见下边持久化
#Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写 操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作 默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可 能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的 持久化特性。Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这 个文件的数据读入内存里,先忽略RDB文件。若开启rdb则将no改为yes appendonly no 指定本地数据库文件名,默认值为 appendonly.aof appendfilename "appendonly.aof" #aof持久化策略的配置 #no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快 #always表示每次写入都执行fsync,以保证数据同步到磁盘 #everysec表示每秒执行一次fsync,可能会导致丢失这1s数据 # appendfsync always appendfsync everysec # appendfsync no # 在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行 fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的 应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。设置为yes表 示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的 默认fsync策略是30秒。可能丢失30秒数据 no-appendfsync-on-rewrite no #aof自动重写配置。当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件 增长到一定大小的时候Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得 到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程 auto-aof-rewrite-percentage 100 #设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写 auto-aof-rewrite-min-size 64mb #aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所 在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项(redis宕机或者异常终止不会造 成尾部不完整现象。)出现这种现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes, 当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis- check-aof修复AOF文件才可以 aof-load-truncated yes #加载redis时,可以识别AOF文件以“redis”开头。 #字符串并加载带前缀的RDB文件,然后继续加载AOF尾巴 aof-use-rdb-preamble yes
-
LUA SCRIPTING
# 如果达到最大时间限制(毫秒),redis会记个log,然后返回error。当一个脚本超过了最大时限。只有 SCRIPT KILL和SHUTDOWN NOSAVE可以用。第一个可以杀没有调write命令的东西。要是已经调用了write,只能 用第二个命令杀 lua-time-limit 5000 -
REDIS CLUSTER
# 集群开关,默认是不开启集群模式 # cluster-enabled yes #集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。这个文件并不需要手动 配置,这个配置文件有Redis生成并更新,每个Redis集群节点需要一个单独的配置文件,请确保与实例运行的系 统中配置文件名称不冲突 # cluster-config-file nodes-6379.conf #节点互连超时的阀值。集群节点超时毫秒数 # cluster-node-timeout 15000 #在进行故障转移的时候,全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间 了,导致数据过于陈旧,这样的slave不应该被提升为master。该参数就是用来判断slave节点与master断线的时 间是否过长。判断方法是: #比较slave断开连接的时间和(node-timeout * slave-validity-factor) + repl-ping-slave-period #如果节点超时时间为三十秒, 并且slave-validity-factor为10,假设默认的repl-ping-slave-period是10 秒,即如果超过310秒slave将不会尝试进行故障转移 # cluster-replica-validity-factor 10 # master的slave数量大于该值,slave才能迁移到其他孤立master上,如这个参数若被设为2,那么只有当一 个主节点拥有2 个可工作的从节点时,它的一个从节点会尝试迁移 # cluster-migration-barrier 1 #默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。设置为no,可以在slot没有全 部分配的时候提供服务。不建议打开该配置,这样会造成分区的时候,小分区的master一直在接受写请求,而 造成很长时间数据不一致 # cluster-require-full-coverage yes
-
CLUSTER DOCKER/NAT
#*群集公告IP #*群集公告端口 #*群集公告总线端口 # Example: # # cluster-announce-ip 10.1.1.5 # cluster-announce-port 6379 # cluster-announce-bus-port 6380
-
SLOW LOG
# slog log是用来记录redis运行中执行比较慢的命令耗时。当命令的执行超过了指定时间,就记录在slow log 中,slog log保存在内存中,所以没有IO操作。 #执行时间比slowlog-log-slower-than大的请求记录到slowlog里面,单位是微秒,所以1000000就是1秒。注 意,负数时间会禁用慢查询日志,而0则会强制记录所有命令。 slowlog-log-slower-than 10000 #慢查询日志长度。当一个新的命令被写进日志的时候,最老的那个记录会被删掉。这个长度没有限制。只要有足 够的内存就行。你可以通过 SLOWLOG RESET 来释放内存 slowlog-max-len 128
-
LATENCY MONITOR
#延迟监控功能是用来监控redis中执行比较缓慢的一些操作,用LATENCY打印redis实例在跑命令时的耗时图表。 只记录大于等于下边设置的值的操作。0的话,就是关闭监视。默认延迟监控功能是关闭的,如果你需要打开,也 可以通过CONFIG SET命令动态设置 latency-monitor-threshold 0 -
EVENT NOTIFICATION
#键空间通知使得客户端可以通过订阅频道或模式,来接收那些以某种方式改动了 Redis 数据集的事件。因为开启键空间通知功能需要消耗一些 CPU ,所以在默认配置下,该功能处于关闭状态。 #notify-keyspace-events 的参数可以是以下字符的任意组合,它指定了服务器该发送哪些类型的通知: ##K 键空间通知,所有通知以 __keyspace@__ 为前缀 ##E 键事件通知,所有通知以 __keyevent@__ 为前缀 ##g DEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知 ##$ 字符串命令的通知 ##l 列表命令的通知 ##s 集合命令的通知 ##h 哈希命令的通知 ##z 有序集合命令的通知 ##x 过期事件:每当有过期键被删除时发送 ##e 驱逐(evict)事件:每当有键因为 maxmemory 政策而被删除时发送 ##A 参数 g$lshzxe 的别名 #输入的参数中至少要有一个 K 或者 E,否则的话,不管其余的参数是什么,都不会有任何 通知被分发。详细使用可以参考http://redis.io/topics/notifications notify-keyspace-events ""
-
ADVANCED CONFIG
# 数据量小于等于hash-max-ziplist-entries的用ziplist,大于hash-max-ziplist-entries用hash hash-max-ziplist-entries 512 # value大小小于等于hash-max-ziplist-value的用ziplist,大于hash-max-ziplist-value用hash hash-max-ziplist-value 64 #-5:最大大小:64 KB<--不建议用于正常工作负载 #-4:最大大小:32 KB<--不推荐 #-3:最大大小:16 KB<--可能不推荐 #-2:最大大小:8kb<--良好 #-1:最大大小:4kb<--良好 list-max-ziplist-size -2 #0:禁用所有列表压缩 #1:深度1表示“在列表中的1个节点之后才开始压缩, #从头部或尾部 #所以:【head】->node->node->…->node->【tail】 #[头部],[尾部]将始终未压缩;内部节点将压缩。 #2:[头部]->[下一步]->节点->节点->…->节点->[上一步]->[尾部] #2这里的意思是:不要压缩头部或头部->下一个或尾部->上一个或尾部, #但是压缩它们之间的所有节点。 #3:[头部]->[下一步]->[下一步]->节点->节点->…->节点->[上一步]->[上一步]->[尾部] list-compress-depth 0 # 数据量小于等于set-max-intset-entries用iniset,大于set-max-intset-entries用set set-max-intset-entries 512 #数据量小于等于zset-max-ziplist-entries用ziplist,大于zset-max-ziplist-entries用zset zset-max-ziplist-entries 128 #value大小小于等于zset-max-ziplist-value用ziplist,大于zset-max-ziplist-value用zset zset-max-ziplist-value 64 #value大小小于等于hll-sparse-max-bytes使用稀疏数据结构(sparse),大于hll-sparse-max-bytes使 用稠密的数据结构(dense)。一个比16000大的value是几乎没用的,建议的value大概为3000。如果对CPU要 求不高,对空间要求较高的,建议设置到10000左右 hll-sparse-max-bytes 3000 #宏观节点的最大流/项目的大小。在流数据结构是一个基数 #树节点编码在这项大的多。利用这个配置它是如何可能#大节点配置是单字节和 #最大项目数,这可能包含了在切换到新节点的时候 # appending新的流条目。如果任何以下设置来设置 # ignored极限是零,例如,操作系统,它有可能只是一集 通过设置限制最大#纪录到最大字节0和最大输入到所需的值 stream-node-max-bytes 4096 stream-node-max-entries 100 #Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用。当你 的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置 为no。如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存 activerehashing yes ##对客户端输出缓冲进行限制可以强迫那些不从服务器读取数据的客户端断开连接,用来强制关闭传输缓慢的客户端。 #对于normal client,第一个0表示取消hard limit,第二个0和第三个0表示取消soft limit,normal client默认取消限制,因为如果没有寻问,他们是不会接收数据的 client-output-buffer-limit normal 0 0 0 #对于slave client和MONITER client,如果client-output-buffer一旦超过256mb,又或者超过64mb持续 60秒,那么服务器就会立即断开客户端连接 client-output-buffer-limit replica 256mb 64mb 60 #对于pubsub client,如果client-output-buffer一旦超过32mb,又或者超过8mb持续60秒,那么服务器就 会立即断开客户端连接 client-output-buffer-limit pubsub 32mb 8mb 60 # 这是客户端查询的缓存极限值大小 # client-query-buffer-limit 1gb #在redis协议中,批量请求,即表示单个字符串,通常限制为512 MB。但是您可以更改此限制。 # proto-max-bulk-len 512mb #redis执行任务的频率为1s除以hz hz 10 #当启用动态赫兹时,实际配置的赫兹将用作作为基线,但实际配置的赫兹值的倍数 #在连接更多客户端后根据需要使用。这样一个闲置的实例将占用很少的CPU时间,而繁忙的实例将反应更灵敏 dynamic-hz yes #在aof重写的时候,如果打开了aof-rewrite-incremental-fsync开关,系统会每32MB执行一次fsync。这 对于把文件写入磁盘是有帮助的,可以避免过大的延迟峰值 aof-rewrite-incremental-fsync yes #在rdb保存的时候,如果打开了rdb-save-incremental-fsync开关,系统会每32MB执行一次fsync。这 对于把文件写入磁盘是有帮助的,可以避免过大的延迟峰值
-
ACTIVE DEFRAGMENTATION
# 已启用活动碎片整理 activedefrag yes # 启动活动碎片整理的最小碎片浪费量 active-defrag-ignore-bytes 100mb # 启动活动碎片整理的最小碎片百分比 active-defrag-threshold-lower 10 # 我们使用最大努力的最大碎片百分比 active-defrag-threshold-upper 100 # 以CPU百分比表示的碎片整理的最小工作量 active-defrag-cycle-min 5 # 在CPU的百分比最大的努力和碎片整理 active-defrag-cycle-max 75 #将从中处理的set/hash/zset/list字段的最大数目 #主词典扫描 active-defrag-max-scan-fields 1000
把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里
- save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘
- **stop-writes-on-bgsave-error :**默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据
- rdbcompression:默认值是yes,redis会采用LZF算法进行压缩、想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大
- **rdbchecksum :**默认值是yes、进行数据校验
- **bfilename :**设置快照的文件名,默认是 dump.rdb
- **dir:**设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在同一目录
- save 阻塞当前Redis服务器
- bgsave 后台异步进行快照操作
备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止
redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save " "
-
优势:
- 保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复
- 会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作
- 恢复大数据集时的速度比 AOF 的恢复速度要快
-
劣势
- 没办法做到实时持久化/秒级持久化
- 版本不兼容(新老版本)
- 一定间隔时间做一次备份、丢失最后一次快照后的所有修改
#Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写
操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可
能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的
持久化特性。Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这
个文件的数据读入内存里,先忽略RDB文件。若开启rdb则将no改为yes
appendonly no
指定本地数据库文件名,默认值为 appendonly.aof
appendfilename "appendonly.aof"
#aof持久化策略的配置
#no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快
#always表示每次写入都执行fsync,以保证数据同步到磁盘
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
# appendfsync always
appendfsync everysec
# appendfsync no
# 在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行
fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的
应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。设置为yes表
示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的
默认fsync策略是30秒。可能丢失30秒数据
no-appendfsync-on-rewrite no
#aof自动重写配置。当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件
增长到一定大小的时候Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得
到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程
auto-aof-rewrite-percentage 100
#设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写
auto-aof-rewrite-min-size 64mb
#aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所
在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项(redis宕机或者异常终止不会造
成尾部不完整现象。)出现这种现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,
当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-
check-aof修复AOF文件才可以
aof-load-truncated yes
#加载redis时,可以识别AOF文件以“redis”开头。
#字符串并加载带前缀的RDB文件,然后继续加载AOF尾巴
aof-use-rdb-preamble yes随着Redis不断的进行,AOF 的文件会越来越大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。为了解决这个问题,Redis新增了重写机制,当** AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩**,只保留可以恢复数据的最小指令集。可以使用命令 bgrewriteaof 来重新
也就是说 AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件
- 子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理其他命令
- 子进程带有父进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性
- Redis 服务器设置了一个 AOF 重写缓冲区、创建子进程后开始使用,当Redis服务器执行一个写命令之后,就会将这个写命令也发送到 AOF 重写缓冲区。当子进程完成 AOF 重写之后,就会给父进程发送一个信号,父进程接收此信号后,就会调用函数将 AOF 重写缓冲区的内容都写到新的 AOF 文件中
优点:
- 提供了多种的同步频率、最多也就丢失 1 秒的数据而已
- Redis 只能向 AOF 文件写入命令的片断,使用 redis-check-aof 工具也很容易修正 AOF 文件
- 可读性较强
缺点:
- 体积更大
- Redis 的负载较高时,RDB 比 AOF 具好更好的性能保证
- 一小段时间内数据的丢失,毫无疑问使用 RDB 、建议不要单独使用某一种持久化机制,而是应该两种一起用
aof-use-rdb-preamble #yes表示开启,设置为no表示禁用| 命令 | 格式 | 作用 | 返回结果 |
|---|---|---|---|
| WATCH | **WATCH | ||
| key [key ...]** | 将给出的Keys标记为监测态,作为事务执行的条件 |
always OK. | |
| UNWATCH | UNWATCH | 清除事务中Keys的 监测态,如果调用了EXEC or DISCARD,则没有必要再手动调用** |
|
| UNWATCH** | always OK. | ||
| MULTI | MULTI | 显式开启redis事务,后续commands将排队,等候使用** |
|
| EXEC**进行原子执行 | always OK. | ||
| EXEC | EXEC | 执行事务中的commands队列,恢复连接状态。如果** |
|
WATCH**在之前被调用,只有监测中的Keys没有被修改,命令才会被执行,否则停止执行(详见下文,CAS机制) |
成功: 返回数组 —— 每个元素对应着原子事务中一个 command的返回结果; ** |
||
失败:** 返回NULL(Ruby 返回nil); |
|||
| DISCARD | DISCARD | 清除事务中的commands队列,恢复连接状态。如果** |
|
WATCH**在之前被调用,释放 监测中的Keys |
always OK. |
注意:WATCH命令的使用是为了解决 事务并发 产生的不可重复读和幻读的问题(简单理解为给Key加锁);
- 所有命令都会被序列化并按顺序执行、执行Redis事务的过程中,不会出现由另一个客户端发出的请求
- 要么全部被处理,要么全部被忽略、当客户端在事务上下文中失去与服务器的连接发生在调用MULTI命令之前、则不执行任何
commands、否则所有的commands都被执行 - redis 使用
AOF(append-only file),使用一个额外的
write操作将事务写入磁盘。如果发生宕机,进程奔溃等情况,可以使用redis-check-aof tool 修复append-only file,使服务正常启动,并恢复部分操作
- 执行 EXEC 之前,入队的命令可能会出错、服务器会对命令入队失败情况进行记录、调用 EXEC 、拒绝执行并自动放弃
- 命令可能在 执行 EXEC 之后失败、其他也会继续执行
一个乐观锁、执行 EXEC 之前、监视任意数量的数据库键、检查如果至少有一个被修改过了、拒绝执行事务
Redis 使用的是客户端-服务器(CS)模型和请求/响应协议的 TCP 服务器,客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。 服务端处理命令,并将结果返回给客户端
由于通信会有网络延迟、没有充分利用 redis 的处理能力、管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回
redis服务器是一个事件驱动型的,主要包括以下两种类型的事件
Redis 采用事件驱动机制来处理大量的网络IO。它并没有使用 libevent 或者 libev 这样的成熟开源方案,而是自己实现一个非常简洁的事件驱动库 ae_event
Redis中的事件驱动库只关注网络IO,以及定时器。该事件库处理下面两类事件:
- 文件事件(file event):用于处理 Redis 服务器和客户端之间的网络IO。
- 时间事件(time eveat):Redis 服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是处理这类定时操作的。
事件驱动库的代码主要是在src/ae.c中实现的,其示意图如下所示
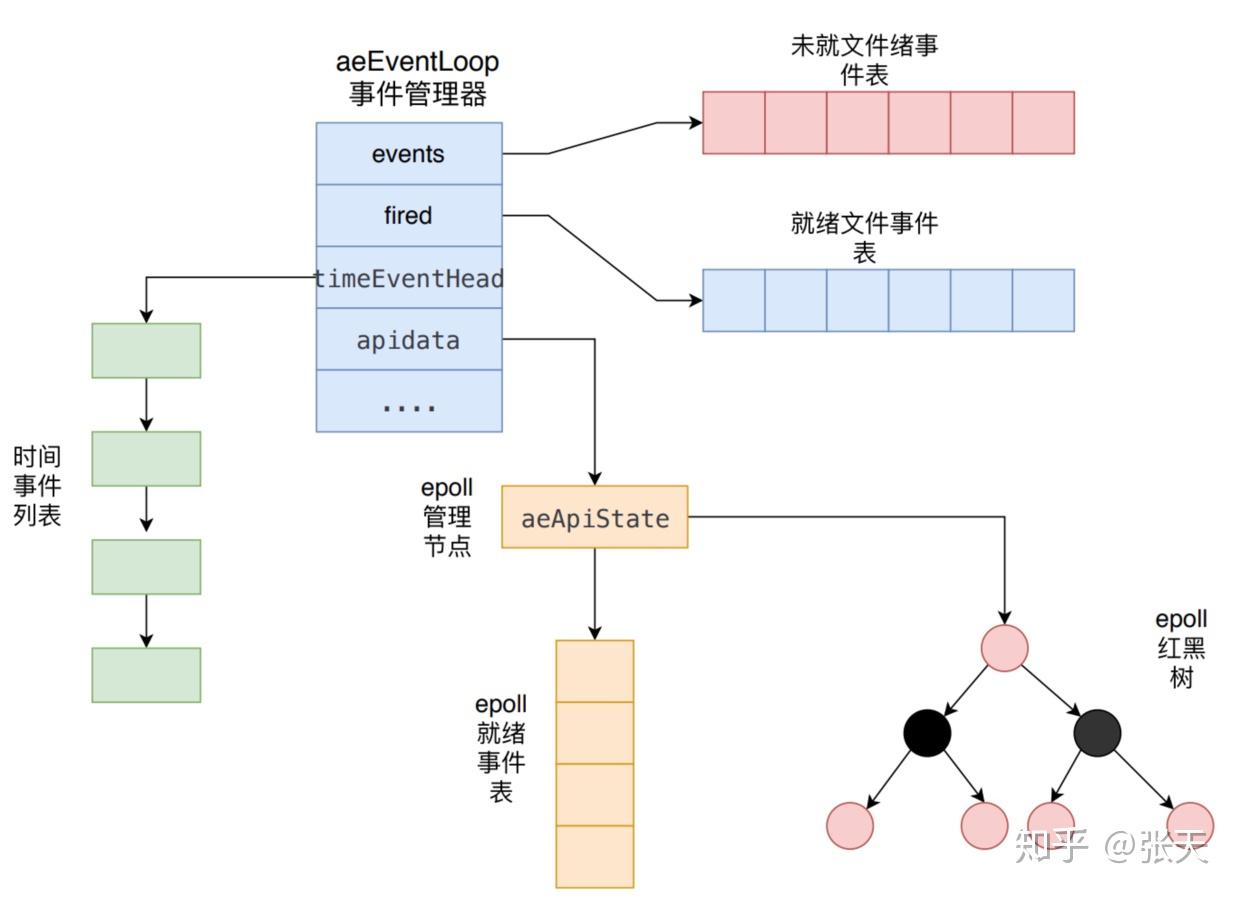
eEventLoop是整个事件驱动的核心,它管理着文件事件表和时间事件列表, 不断地循环处理着就绪的文件事件和到期的时间事件。
Redis基于Reactor模式开发了自己的网络事件处理器,也就是文件事件处理器。文件事件处理器使用IO多路复用技术,同时监听多个套接字,并为套接字关联不同的事件处理函数。当套接字的可读或者可写事件触发时,就会调用相应的事件处理函数
Redis基于Reactor模式开发了自己的网络事件处理器,也就是文件事件处理器。文件事件处理器使用IO多路复用技术,同时监听多个套接字,并为套接字关联不同的事件处理函数。当套接字的可读或者可写事件触发时,就会调用相应的事件处理函数。
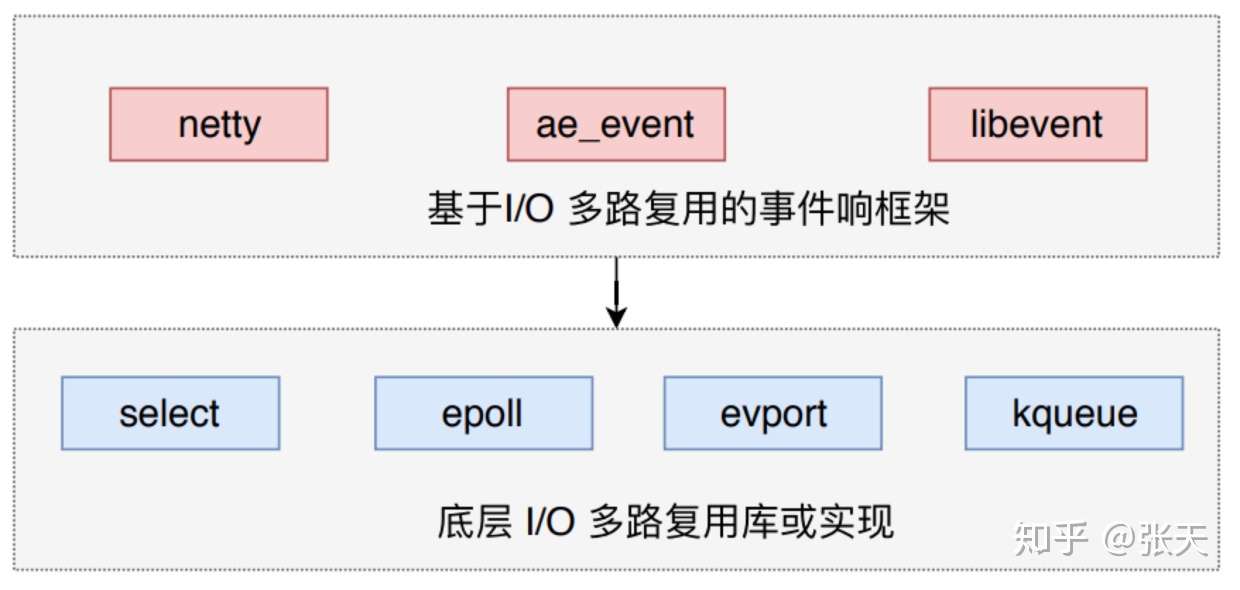
Redis 使用的IO多路复用技术主要有: select、 epoll、 evport和 kqueue等。每个IO多路复用函数库在 Redis 源码中都对应一个单独的文件,比如aeselect.c,aeepoll.c,
ae_kqueue.c等。Redis 会根据不同的操作系统,按照不同的优先级选择多路复用技术。事件响应框架一般都采用该架构,比如 netty 和 libevent。
如下图所示,文件事件处理器有四个组成部分,它们分别是套接字、I/O多路复用程序、文件事件分派器以及事件处理器。
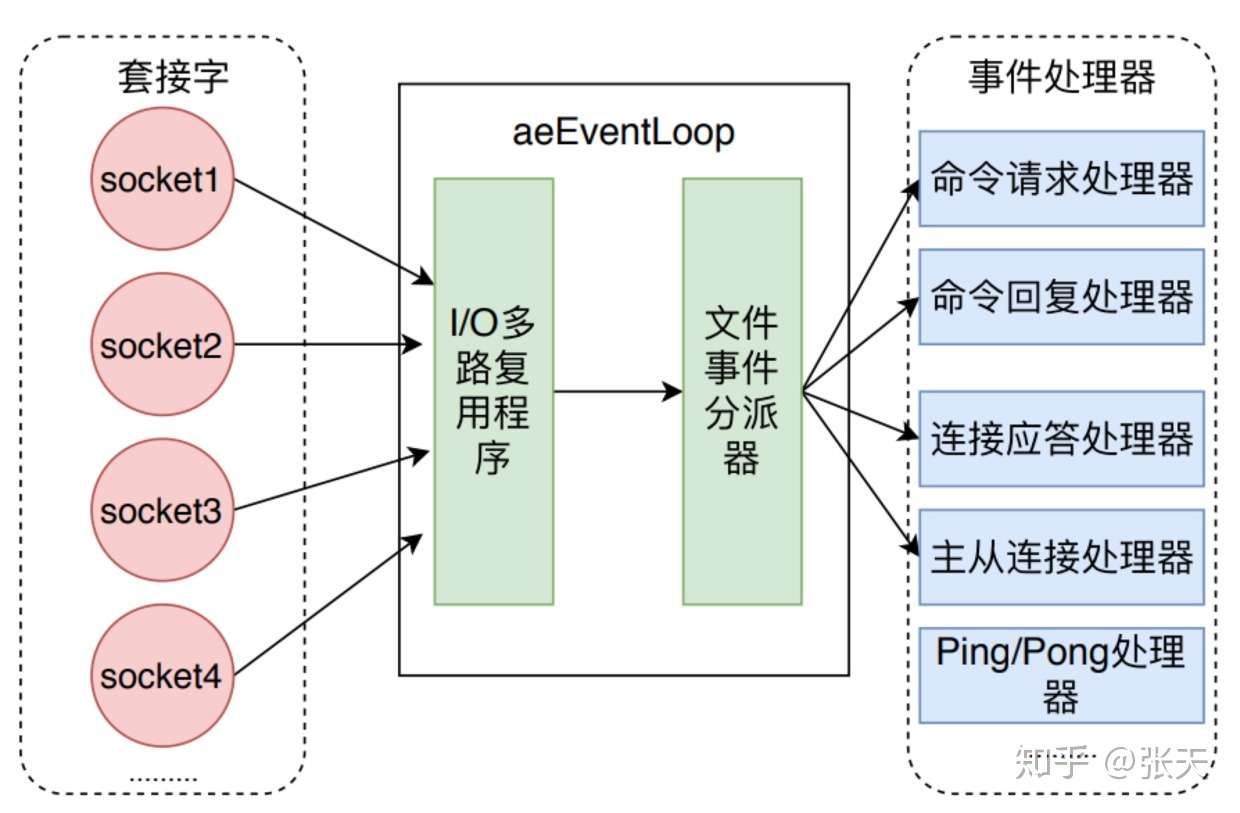
文件事件是对套接字操作的抽象,每当一个套接字准备好执行 accept、read、write和 close 等操作时,就会产生一个文件事件。因为 Redis 通常会连接多个套接字,所以多个文件事件有可能并发的出现。
I/O多路复用程序负责监听多个套接字,并向文件事件派发器传递那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生的套接字都放到同一个队列(也就是后文中描述的 aeEventLoop的 fired就绪事件表)
里边,然后文件事件处理器会以有序、同步、单个套接字的方式处理该队列中的套接字,也就是处理就绪的文件事件。
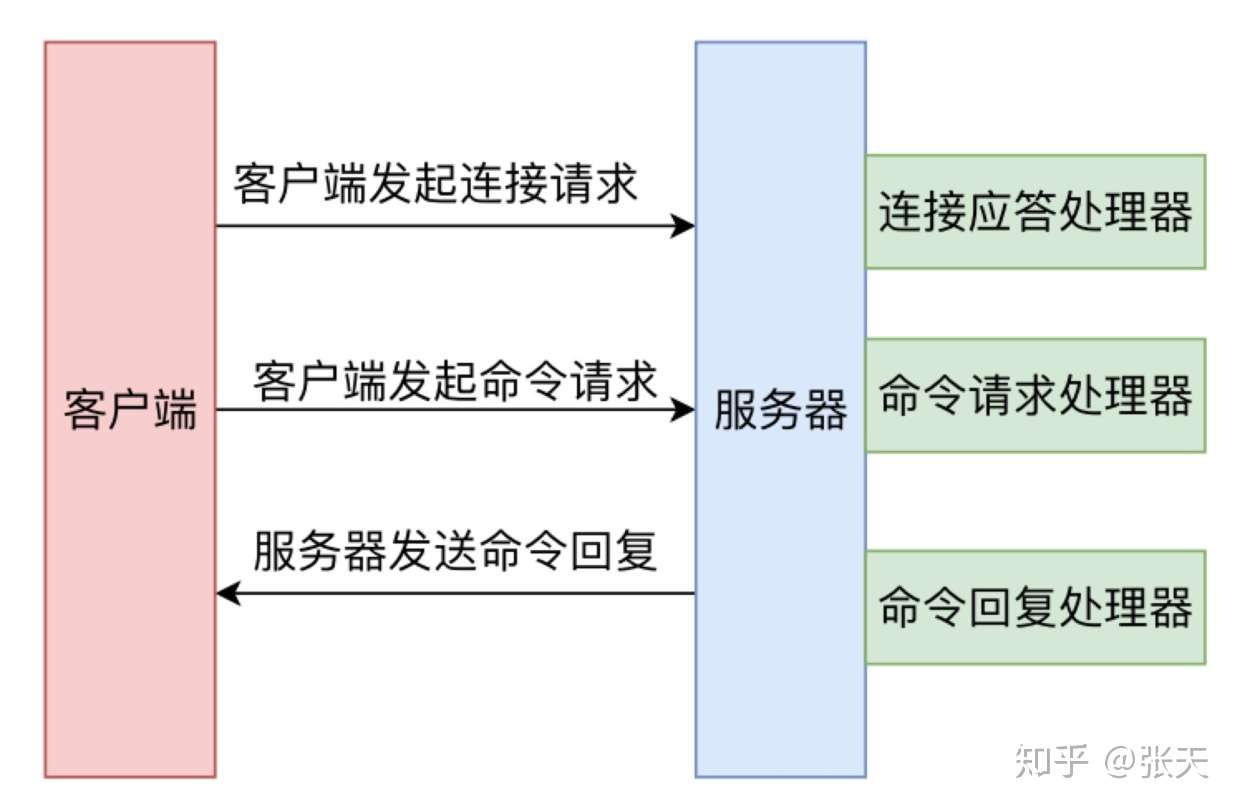
所以,一次 Redis 客户端与服务器进行连接并且发送命令的过程如上图所示。
- 客户端向服务端发起建立 socket 连接的请求,那么监听套接字将产生 AEREADABLE 事件,触发连接应答处理器执行。处理器会对客户端的连接请求进行应答,然后创建客户端套接字,以及客户端状态,并将客户端套接字的 AE READABLE 事件与命令请求处理器关联。
- 客户端建立连接后,向服务器发送命令,那么客户端套接字将产生 AE_READABLE 事件,触发命令请求处理器执行,处理器读取客户端命令,然后传递给相关程序去执行。
- 执行命令获得相应的命令回复,为了将命令回复传递给客户端,服务器将客户端套接字的 AEWRITEABLE 事件与命令回复处理器关联。当客户端试图读取命令回复时,客户端套接字产生 AEWRITEABLE 事件,触发命令** 回复处理器**将命令回复全部写入到套接字中。
Redis 的时间事件分为以下两类:
- 定时事件:让一段程序在指定的时间之后执行一次。
- 周期性事件:让一段程序每隔指定时间就执行一次。
Redis 的时间事件的具体定义结构如下所示。
typedef struct aeTimeEvent {
/* 全局唯一ID */
long long id; /* time event identifier. */
/* 秒精确的UNIX时间戳,记录时间事件到达的时间*/
long when_sec; /* seconds */
/* 毫秒精确的UNIX时间戳,记录时间事件到达的时间*/
long when_ms; /* milliseconds */
/* 时间处理器 */
aeTimeProc *timeProc;
/* 事件结束回调函数,析构一些资源*/
aeEventFinalizerProc *finalizerProc;
/* 私有数据 */
void *clientData;
/* 前驱节点 */
struct aeTimeEvent *prev;
/* 后继节点 */
struct aeTimeEvent *next;
} aeTimeEvent;一个时间事件是定时事件还是周期性事件取决于时间处理器的返回值:
- 如果返回值是 AE_NOMORE,那么这个事件是一个定时事件,该事件在达到后删除,之后不会再重复。
- 如果返回值是非 AE_NOMORE 的值,那么这个事件为周期性事件,当一个时间事件到达后,服务器会根据时间处理器的返回值,对时间事件的
when属性进行更新,让这个事件在一段时间后再次达到。
Redis 将所有时间事件都放在一个无序链表中,每次 Redis 会遍历整个链表,查找所有已经到达的时间事件,并且调用相应的事件处理器。
介绍完文件事件和时间事件,我们接下来看一下 aeEventLoop的具体实现。
Redis 服务端在其初始化函数 initServer中,会创建事件管理器 aeEventLoop对象。
函数 aeCreateEventLoop将创建一个事件管理器,主要是初始化 aeEventLoop的各个属性值,比如 events、 fired、 timeEventHead和 apidata:
- 首先创建
aeEventLoop对象。 - 初始化未就绪文件事件表、就绪文件事件表。
events指针指向未就绪文件事件表、fired指针指向就绪文件事件表。表的内容在后面添加具体事件时进行初变更。 - 初始化时间事件列表,设置
timeEventHead和timeEventNextId属性。 - 调用
aeApiCreate函数创建epoll实例,并初始化apidata。
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
/* 创建事件状态结构 */
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
/* 创建未就绪事件表、就绪事件表 */
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
if (eventLoop->events == NULL || eventLoop->fired == NULL) goto err;
/* 设置数组大小 */
eventLoop->setsize = setsize;
/* 初始化执行最近一次执行时间 */
eventLoop->lastTime = time(NULL);
/* 初始化时间事件结构 */
eventLoop->timeEventHead = NULL;
eventLoop->timeEventNextId = 0;
eventLoop->stop = 0;
eventLoop->maxfd = -1;
eventLoop->beforesleep = NULL;
eventLoop->aftersleep = NULL;
/* 将多路复用io与事件管理器关联起来 */
if (aeApiCreate(eventLoop) == -1) goto err;
/* 初始化监听事件 */
for (i = 0; i < setsize; i++)
eventLoop->events[i].mask = AE_NONE;
return eventLoop;
err:
.....
}aeApiCreate 函数首先创建了 aeApiState对象,初始化了epoll就绪事件表;然后调用 epoll_create创建了 epoll实例,最后将该 aeApiState赋值给 apidata属性。
aeApiState对象中 epfd存储 epoll的标识, events是一个 epoll就绪事件数组,当有 epoll事件发生时,所有发生的 epoll
事件和其描述符将存储在这个数组中。这个就绪事件数组由应用层开辟空间、内核负责把所有发生的事件填充到该数组。
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
/* 初始化epoll就绪事件表 */
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
/* 创建 epoll 实例 */
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
/* 事件管理器与epoll关联 */
eventLoop->apidata = state;
return 0;
}
typedef struct aeApiState {
/* epoll_event 实例描述符*/
int epfd;
/* 存储epoll就绪事件表 */
struct epoll_event *events;
} aeApiState;aeFileEvent是文件事件结构,对于每一个具体的事件,都有读处理函数和写处理函数等。Redis 调用 aeCreateFileEvent函数针对不同的套接字的读写事件注册对应的文件事件。
typedef struct aeFileEvent {
/* 监听事件类型掩码,值可以是 AE_READABLE 或 AE_WRITABLE */
int mask;
/* 读事件处理器 */
aeFileProc *rfileProc;
/* 写事件处理器 */
aeFileProc *wfileProc;
/* 多路复用库的私有数据 */
void *clientData;
} aeFileEvent;
/* 使用typedef定义的处理器函数的函数类型 */
typedef void aeFileProc(struct aeEventLoop *eventLoop,
int fd, void *clientData, int mask);比如说,Redis 进行主从复制时,从服务器需要主服务器建立连接,它会发起一个 socekt连接,然后调用 aeCreateFileEvent
函数针对发起的socket的读写事件注册了对应的事件处理器,也就是 syncWithMaster函数。
aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL);
/* 符合aeFileProc的函数定义 */
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {....}aeCreateFileEvent的参数 fd指的是具体的 socket套接字, proc指 fd产生事件时,具体的处理函数, clientData
则是回调处理函数时需要传入的数据。 aeCreateFileEvent主要做了三件事情:
- 以
fd为索引,在events未就绪事件表中找到对应事件。 - 调用
aeApiAddEvent函数,该事件注册到具体的底层 I/O 多路复用中,本例为epoll。 - 填充事件的回调、参数、事件类型等参数。
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
/* 取出 fd 对应的文件事件结构, fd 代表具体的 socket 套接字 */
aeFileEvent *fe = &eventLoop->events[fd];
/* 监听指定 fd 的指定事件 */
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
/* 置文件事件类型,以及事件的处理器 */
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
/* 私有数据 */
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}如上文所说,Redis 基于的底层 I/O 多路复用库有多套,所以 aeApiAddEvent也有多套实现,下面的源码是 epoll下的实现。其核心操作就是调用 epoll的 epoll_ctl函数来向 epoll
注册响应事件。有关 epoll
相关的知识可以看一下《Java NIO源码分析》
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* 如果 fd 没有关联任何事件,那么这是一个 ADD 操作。如果已经关联了某个/某些事件,那么这是一个 MOD 操作。 */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
/* 注册事件到 epoll */
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
/* 调用epoll_ctl 系统调用,将事件加入epoll中 */
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}因为 Redis 中同时存在文件事件和时间事件两个事件类型,所以服务器必须对这两个事件进行调度,决定何时处理文件事件,何时处理时间事件,以及如何调度它们。
aeMain函数以一个无限循环不断地调用 aeProcessEvents函数来处理所有的事件。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
/* 如果有需要在事件处理前执行的函数,那么执行它 */
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
/* 开始处理事件*/
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}下面是 aeProcessEvents的伪代码,它会首先计算距离当前时间最近的时间事件,以此计算一个超时时间;然后调用 aeApiPoll函数去等待底层的I/O多路复用事件就绪; aeApiPoll
函数返回之后,会处理所有已经产生文件事件和已经达到的时间事件。
/* 伪代码 */
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
/* 获取到达时间距离当前时间最接近的时间事件*/
time_event = aeSearchNearestTimer();
/* 计算最接近的时间事件距离到达还有多少毫秒*/
remaind_ms = time_event.when - unix_ts_now();
/* 如果事件已经到达,那么remaind_ms为负数,将其设置为0 */
if (remaind_ms < 0) remaind_ms = 0;
/* 根据 remaind_ms 的值,创建 timeval 结构*/
timeval = create_timeval_with_ms(remaind_ms);
/* 阻塞并等待文件事件产生,最大阻塞时间由传入的 timeval 结构决定,如果remaind_ms 的值为0,则aeApiPoll 调用后立刻返回,不阻塞*/
/* aeApiPoll调用epoll_wait函数,等待I/O事件*/
aeApiPoll(timeval);
/* 处理所有已经产生的文件事件*/
processFileEvents();
/* 处理所有已经到达的时间事件*/
processTimeEvents();
}与 aeApiAddEvent类似, aeApiPoll也有多套实现,它其实就做了两件事情,调用 epoll_wait阻塞等待 epoll
的事件就绪,超时时间就是之前根据最快达到时间事件计算而来的超时时间;然后将就绪的 epoll事件转换到fired就绪事件。 aeApiPoll就是上文所说的I/O多路复用程序。具体过程如下图所示。
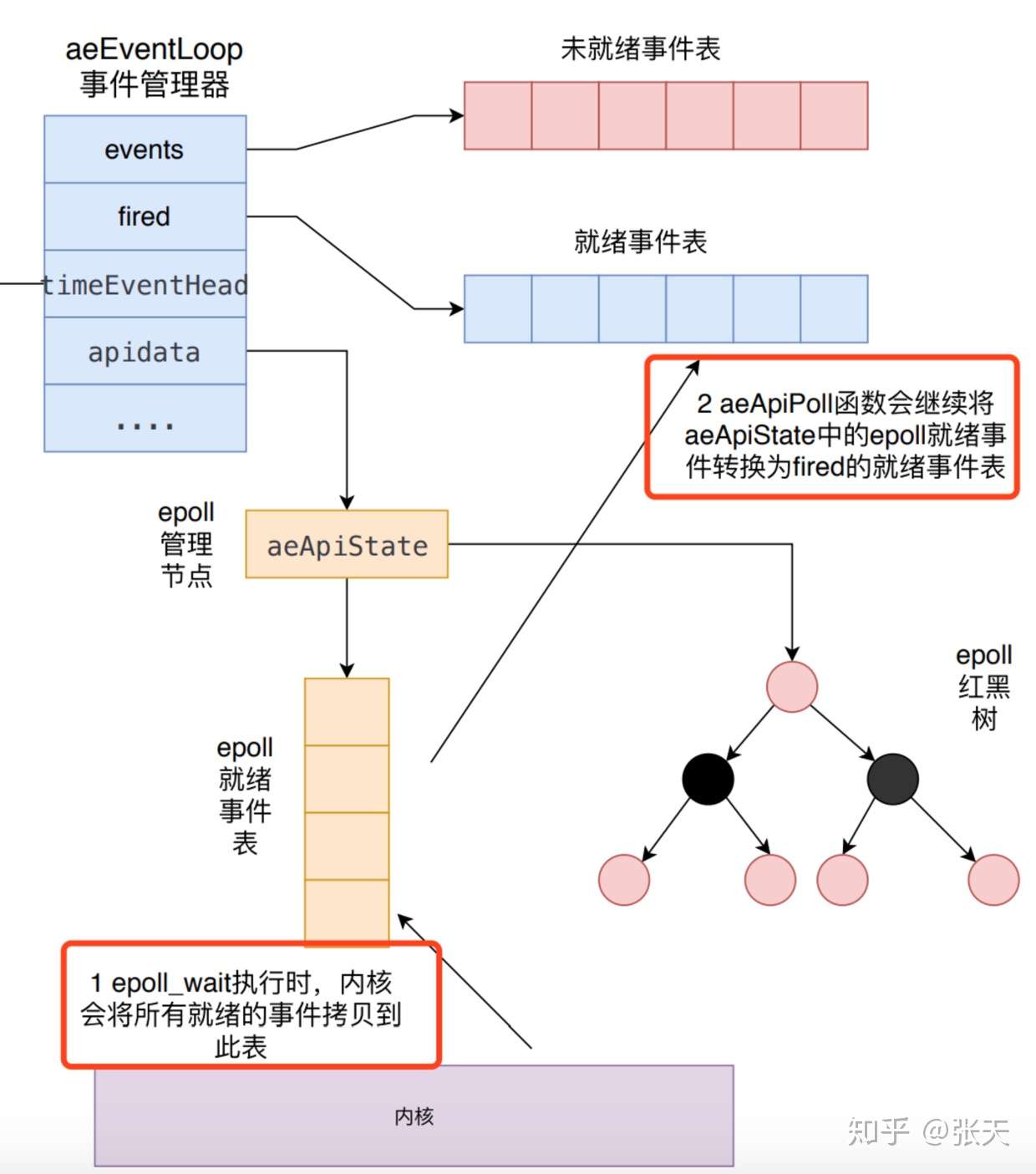
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
{
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
// 调用epoll_wait函数,等待时间为最近达到时间事件的时间计算而来。
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
// 有至少一个事件就绪?
if (retval > 0) {
int j;
/*为已就绪事件设置相应的模式,并加入到 eventLoop 的 fired 数组中*/
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN)
mask |= AE_READABLE;
if (e->events & EPOLLOUT)
mask |= AE_WRITABLE;
if (e->events & EPOLLERR)
mask |= AE_WRITABLE;
if (e->events & EPOLLHUP)
mask |= AE_WRITABLE;
/* 设置就绪事件表元素 */
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
// 返回已就绪事件个数
return numevents;
}processFileEvent是处理就绪文件事件的伪代码,也是上文所述的文件事件分派器,它其实就是遍历 fired就绪事件表,然后根据对应的事件类型来调用事件中注册的不同处理器,读事件调用 rfileProc
,而写事件调用 wfileProc。
void processFileEvent(int numevents) {
for (j = 0; j < numevents; j++) {
/* 从已就绪数组中获取事件 */
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int fired = 0;
int invert = fe->mask & AE_BARRIER;
/* 读事件 */
if (!invert && fe->mask & mask & AE_READABLE) {
/* 调用读处理函数 */
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
/* 写事件. */
if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
if (invert && fe->mask & mask & AE_READABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
processed++;
}
}
}而 processTimeEvents是处理时间事件的函数,它会遍历 aeEventLoop的事件事件列表,如果时间事件到达就执行其 timeProc函数,并根据函数的返回值是否等于 AE_NOMORE
来决定该时间事件是否是周期性事件,并修改器到达时间。
static int processTimeEvents(aeEventLoop *eventLoop) {
int processed = 0;
aeTimeEvent *te;
long long maxId;
time_t now = time(NULL);
....
eventLoop->lastTime = now;
te = eventLoop->timeEventHead;
maxId = eventLoop->timeEventNextId-1;
/* 遍历时间事件链表 */
while(te) {
long now_sec, now_ms;
long long id;
/* 删除需要删除的时间事件 */
if (te->id == AE_DELETED_EVENT_ID) {
aeTimeEvent *next = te->next;
if (te->prev)
te->prev->next = te->next;
else
eventLoop->timeEventHead = te->next;
if (te->next)
te->next->prev = te->prev;
if (te->finalizerProc)
te->finalizerProc(eventLoop, te->clientData);
zfree(te);
te = next;
continue;
}
/* id 大于最大maxId,是该循环周期生成的时间事件,不处理 */
if (te->id > maxId) {
te = te->next;
continue;
}
aeGetTime(&now_sec, &now_ms);
/* 事件已经到达,调用其timeProc函数*/
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
int retval;
id = te->id;
retval = te->timeProc(eventLoop, id, te->clientData);
processed++;
/* 如果返回值不等于 AE_NOMORE,表示是一个周期性事件,修改其when_sec和when_ms属性*/
if (retval != AE_NOMORE) {
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else {
/* 一次性事件,标记为需删除,下次遍历时会删除*/
te->id = AE_DELETED_EVENT_ID;
}
}
te = te->next;
}
return processed;
}当不在需要某个事件时,需要把事件删除掉。例如: 如果fd同时监听读事件、写事件。当不在需要监听写事件时,可以把该fd的写事件删除。
aeDeleteEventLoop函数的执行过程总结为以下几个步骤
- 根据
fd在未就绪表中查找到事件 - 取消该
fd对应的相应事件标识符 - 调用
aeApiFree函数,内核会将epoll监听红黑树上的相应事件监听取消
-
Bitmaps
- 获取指定key对应偏移量上的bit值 getbit key offset
- 设置指定key对应偏移量上的bit值,value只能是1或0 setbit key offset value
- 对指定key按位进行交、并、非、异或操作,并将结果保存到destKey中
-
HyperLogLog(redis 应用于独立信息统计)
- 据集去重后元素个数
- 核心是基数估算算法,最终数值存在一定误差
-
GEO(redis 应用于地理位置计算)
-
添加坐标点
-
获取坐标点
-
计算坐标点距离
-
根据坐标求范围内的数据
-
根据点求范围内数据
-
获取指定点对应的坐标hash值
-
-
尽量使用短的key
-
避免使用keys *、这个命令是阻塞的、可以去使用SCAN,来代替
-
存到Redis之前数据压缩下
-
设置key有效期
-
选择回收策略
-
使用bit位级别操作和byte字节级别操作来减少不必要的内存使用
-
尽可能地使用hashes哈希存储
应用场景:存储一个用户信息对象数据
用法一:
-
将用户 ID 作为查找 key,把其他信息封装成一个对象以序列化的方式存储
增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题
用法二:
- 用户信息对象有多少成员就存成多少个 key-value 对儿,用用户 ID +对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题、但是用户 ID 为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的、但是如果内部 Map 的成员很多,那么涉及到遍历整个内部 Map 的操作,由于 Redis 单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应
用法三:
-
Key 仍然是用户 ID、value 是一个 Map,这个 Map 的 key 是成员的属性名,value 是属性值
Hash结构存储在单个Hash元素在不足一定数量时进行压缩存储、我们将每一张图片ID为作key,用户uid作为value来存成key-value对、具体的做法就是将数据分段,每一段使用一个Hash结构存储,由于Hash结构会在单个Hash元素在不足一定数量时进行压缩存储
-
-
sorted set 的内部使用 HashMap 和跳跃表(SkipList)来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单
-
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构
-
业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能
-
想要一次添加多条数据的时候可以使用管道
-
限制redis的内存大小
一类是主数据库(master),另一类是从数据库(slave)、主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库、从数据库一般是只读的,并接受主数据库同步过来的数据
-
主从复制原理:
-
启动成功后,连接主数据库,发送 SYNC 命令
-
执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令
-
主数据库 BGSAVE 执行完后,向所有从数据库发送快照文件,并在发送期间继续记录被执行的写命令
-
收到快照文件后丢弃所有旧数据,载入收到的快照
-
开始接收命令请求,并执行来自主数据库缓冲区的写命令
-
每执行一个写命令就会向从数据库发送相同的写命令
-
断开重连后,2.8之后的版本会将断线期间的命令传给重数据库
-
优点:
- 进行读写分离
- 分载 Master 的读操作压力
- Slave 同样可以接受其它 Slaves 的连接和同步请求(多层slave)
- Master Server、Slave Server 均为非阻塞
-
缺点:
- 不具备自动容错和恢复功能、主机从机的宕机都会导致前端部分读写请求失败、需要手动把一台从服务器切换为主服务器
- 宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题
- 多个 Slave 断线、同一时间段进行重启、导致 Master IO 剧增从而宕机
- 较难支持在线扩容
-
一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例
-
哨兵运行原理:
- 发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器
- 监测到 master 宕机、过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机
- 一个哨兵进程对Redis服务器进行监控,也可能会出现问题、用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式
-
故障切换过程
假设主服务器宕机、哨兵1先检测到这个结果(改变询问频率: 10 秒变成1秒)、认为主服务器不可用,这个现象成为主观下线、向同样监视这个Master的其它Sentinel进行询问、接收到足够数量的已下线判断之后,Sentinel就会将从服务器判断为客观下线,并对主服务器执行故障转移、没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master 主服务器的客观下线状态就会被移除。若 Master 主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除
- 优点:
- 自动版的主从复制
- 缺点:
- 难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
- 优点:
实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容
任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作
有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是 cluster,可以理解为是一个集群管理的插件
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是 cluster,可以理解为是一个集群管理的插件
redis-cluster集群引入了主从复制模型、一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
集群特点:
- 所有的 redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效
- 客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
twitter 开源的一个 redis 和 memcache 的 中间代理服务器 程序、接受来自多个程序的访问,按照 路由规则,转发给后台的各个 Redis 服务器,再原路返回。Twemproxy 存在 单点故障
问题,需要结合 Lvs 和 Keepalived 做 高可用方案
-
定时删除
一个定时器,当key设置有过期时间,且过期时间到达时,由定时器任务立即执行对键的删除操作
优点:节约内存,到时就删除,快速释放掉不必要的内存占用
缺点:CPU压力很大,无论CPU此时负载多高,均占用CPU,会影响redis服务器响应时间和指令吞吐量
-
惰性删除
数据到达过期时间,不做处理。等下次访问该数据时发现以过期,删除,返回不存在
优点:节约CPU性能,发现必须删除的时候才删除
缺点:内存压力很大,出现长期占用内存数据
-
定期删除
周期性轮询redis库中的时效型数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
CPU性能占用设置有峰值,检测频度可自定义设置。内存压力不是很大,长期占用内存的数据会被持续清理
多路 指的是多个网络连接客户端,复用 指的是复用同一个线程(单进程)
多路复用其实是使用一个线程来检查多个Socket的就绪状态,在单个线程中通过记录跟踪每一个socket(I/O流)的状态来管理处理多个I/O流
- 一个socket客户端与服务端连接时,会生成对应一个套接字描述符、每一个socket网络连接其实都对应一个文件描述符
- 多个客户端与服务端连接时,Redis使用 I/O多路复用程序 将客户端socket对应的FD注册到监听列表(一个队列)中、客服端执行read、write等操作命令时,I/O多路复用程序会将命令封装成一个事件,并绑定到对应的FD上
- 多路复用模块同时监控多个文件描述符(fd)的读写情况,当
accept、read、write和close文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器进行处理相关命令操作
nginx+lua访问流量实时上报kafka
操作步骤:
- 在nginx这一层,接收到访问请求的时候,就把请求的流量上报发送给kafka
- 单独的线程消费,写入队列
- 日志解析bolt
- 商品访问次数统计bolt
- 基于LRUMap完成统计
在某一个时间段内,缓存集中过期失效。Redis 宕机!缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
解决方案:
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送信息,订阅者(pub)接收信息
订阅/发布消息示意图:
第一个:消息发送者
第二个:频道
第三个:消息接收者
下图展示了频道 channel1,以及订阅这个频道的三个客户端--client2、client5和client1 的关系
当有新消息通过 PUBLISH 命令发送给频道 channel1 时,这个消息就会被发送给订阅它的三个客户端
命令
| 序号 | 命令及描述 |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ...] 订阅一个或多个符合给定模式的频道。 |
| 2 | [PUBSUB subcommand argument [argument ...]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | [PUNSUBSCRIBE pattern [pattern ...]] 退订所有给定模式的频道。 |
| 5 | [SUBSCRIBE channel channel ...] 订阅给定的一个或多个频道的信息。 |
| 6 | [UNSUBSCRIBE channel [channel ...]] 指退订给定的频道。 |
原理:
这些命令被广泛用于构建即时通信应用,比如网络聊天室、是实时广播和实时提醒等
使用场景:
1、实时消息系统
2、实时聊天
3、订阅、关注系统
概念:
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);
数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡 :在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
默认情况下,每台 Redis 服务器都是主节点;一般情况下只配置从机就好了
真正的主从配置应该在配置文件中;配置,这样就是永久的
细节
- 主机可以写,从机不能写只能读取
- 主机断开连接、从机依旧连接到主机的,但是没有写操作;主机回来了仍然能获取到主机写的信息
复制原理
Slave 启动成功连接到 master 后会发送一个 sync 同步命令
Master 接到命令,启动后台的存盘进程,同时手机所有接受到的修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:slave 服务接受到数据库文件数据后,将其存盘并加载到内存中
增量复制:Master 继续将新的所有收集到的修改命令传送给slave。完成同步
只要是重连 master,一次完全同步(全量复制)将被自动执行!数据一定会在从机中看到
层层链路
上一个 M 连接下一个 S!
如果主机断开连接,可以使用 SLAVEOF no one 让自己变成主机!其他的节点就可以手动连接到最新的这个主节点!如果这个时候老大修复了,那就重新连接!
概述
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。

然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线 。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为** 客观下线**。这样对于客户端而言,一切都是透明的。
测试!
1、配置哨兵配置文件
# sentinel monitor 被监控的名称 host port 1
sentinel monitor myredis 127.0.01 6379 1后边的这个数字1,代表主机挂了,slave投票看让谁接替成为主机,票数最多的,就会成为主机!
如果 Master 节点断开了,这个时候就会从从机中随机选择一个服务器(投票算法)
哨兵模式
如果主机此时后来了,只能归并到新的主机下,当做从机,这就是哨兵的规则!
优点:
- 哨兵集群,基于中主从复制模式,所有的主从配置优点,全有
- 主从可以切换,故障可以转移,系统可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动,更加强壮
缺点:
- Redis 不好在线扩容,集群容量到达上限,扩容很麻烦
- 配置很麻烦,有很多选择
2、启动哨兵!
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当** 用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透**(==缓存穿透是指缓存和数据库中都没有的数据==)
解决方案
-
布隆过滤器
一种数据结构,对多有可能查询的参数以hash形式存储,在控制层先进行校验,不符合就丢弃,避免了对底层存储系统的压力
-
缓存空对象
当存储层不命中后,及时返回空对象也将其缓存起来,设置一个会过期时间,之后就会从缓存中获取,保护了后端数据源
存在问题:
- 空值被缓存,意味着缓存更多空值得键
- 即使对空值设置了过期时间,还是会存在 缓存层 和 存储层的数据会有一端时间窗口的不一致,对于需要保持一致性的业务有影响
==*缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期)*==,这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案
-
设置热点数据永远不过期
-
加互斥锁
分布式锁:保证每个key同时只有一个线程区查询后台服务,其他线程没有获得分布式锁的权限,因此只需要等待。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁考验很大。
在某一个时间段内,缓存集中过期失效。Redis 宕机!缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
解决方案
-
redis 高可用(本质上及时搭建集群)
-
限流降级
- 计数器并发数限流:使用共享变量实现
- 信号量:使用java中的Semaphore
-
QPS限流
- 计数器法:实现简单,精度不高,重置节点时无法处理突发请求
- 滑动窗口:滑动窗口的窗口越小,则精度越高,相应的资源消耗也更高。
- 漏桶算法 : 限制的是流出速率,突发请求要排队,对服务保护较好;流入随机,流出固定
- 令牌桶算法 :限制的是平均流入速率,允许一定程度突发请求(无需排队)
缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量,比如对于某个key只允许一盒现成查询数据和写缓存,其他线程等待。
-
数据预热
正式部署之前,把可能的数据先预访问一遍,这样部分可能大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的点尽量均匀。
分布式锁特点:
- 互斥性: 同一时刻只能有一个线程持有锁
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
public String defaultStock() throws InterruptedException {
String lockKey = "product_001";
String clientId = UUID.randomUUID().toString();
try {
Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 1, TimeUnit.SECONDS);
if (!result) {
System.out.println("当前抢购人数过多");
return "error";
}
int stock = Integer.valueOf(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))){
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}public String defaultRedissionStock() throws InterruptedException {
String lockKey = "product_001";
RLock redissonLock = redisson.getLock(lockKey);
try {
redissonLock.lock(30, TimeUnit.SECONDS);
int stock = Integer.valueOf(stringRedisTemplate.opsForValue().get("stock"));
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + "");
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} finally {
redissonLock.unlock();
}
return "end";
}使用 Redssion 主从架构 (redis QPS 接近10w、会导致锁 失效)
- ZooKeeper
- 超过半数加锁成功才证明加锁成功(RedLock)、也就是一个客户端同时向多个redis执行加锁操作
- 利用setnx+expire命令(两步操作、不能保证原子性)
- 使用Lua脚本(包含setnx和expire两条指令)
- 2.6.12 版本开始、 SET 命令增加一系列选项(et命令的nx选项,就等同于setnx命令,value必须要具有唯一性,我们可以用UUID来做)
- 客户端1获取锁成功
- 客户端1在某个操作上阻塞了太长时间
- 设置的key过期了,锁自动释放了
- 客户端2获取到了对应同一个资源的锁
- 客户端1从阻塞中恢复过来,因为value值一样,所以执行释放锁操作时就会释放掉客户端2持有的锁,这样就会造成问题
- Redlock算法 与 Redisson 实现
释放锁时需要验证value值,也就是说我们在获取锁的时候需要设置一个value,不能直接用del key这种粗暴的方式, 因为直接del key任何客户端都可以进行解锁了,所以解锁时,我们需要判断锁是否是自己的,基于value值来判断
-
自定义注解(被注解的方法会执行获取分布式锁的逻辑)
@Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Inherited public @interface RedisLock { //锁定的资源,redis的键 String value() default "default"; //锁定保持时间(以毫秒为单位) long keepMills() default 30000; //失败时执行的操作 LockFailAction action() default LockFailAction.CONTINUE; //失败时执行的操作--枚举 public enum LockFailAction{ GIVEUP, CONTINUE; } //重试的间隔 long sleepMills() default 200; //重试次数 int retryTimes() default 5; }
-
具有分布式锁的Bean
@Configuration @AutoConfigureAfter(RedisAutoConfiguration.class) public class DistributedLockAutoConfiguration { @Bean @ConditionalOnBean(RedisTemplate.class) public DistributedLock redisDistributedLock(RedisTemplate redisTemplate){ return new RedisDistributedLock(redisTemplate); } }
-
面向切面编程-定义切面
@Aspect @Configuration @ConditionalOnClass(DistributedLock.class) @AutoConfigureAfter(DistributedLockAutoConfiguration.class) public class DistributedLockAspectConfiguration { private final Logger logger = LoggerFactory.getLogger(DistributedLockAspectConfiguration.class); @Autowired private DistributedLock distributedLock; @Pointcut("@annotation(com.itopener.lock.redis.spring.boot.autoconfigure.annotations.RedisLock)") private void lockPoint(){ } @Around("lockPoint()") public Object around(ProceedingJoinPoint pjp) throws Throwable{ Method method = ((MethodSignature) pjp.getSignature()).getMethod(); RedisLock redisLock = method.getAnnotation(RedisLock.class); String key = redisLock.value(); if(StringUtils.isEmpty(key)){ Object\[\] args = pjp.getArgs(); key = Arrays.toString(args); } int retryTimes = redisLock.action().equals(LockFailAction.CONTINUE) ? redisLock.retryTimes() : 0; //获取分布式锁 boolean lock = distributedLock.lock(key, redisLock.keepMills(), retryTimes, redisLock.sleepMills()); if(!lock) { logger.debug("get lock failed : " + key); return null; } //执行方法之后,释放分布式锁 logger.debug("get lock success : " + key); try { return pjp.proceed(); //执行方法 } catch (Exception e) { logger.error("execute locked method occured an exception", e); } finally { boolean releaseResult = distributedLock.releaseLock(key); //释放分布式锁 logger.debug("release lock :" + key + (releaseResult ?" success" : "failed")); } return null; } }